

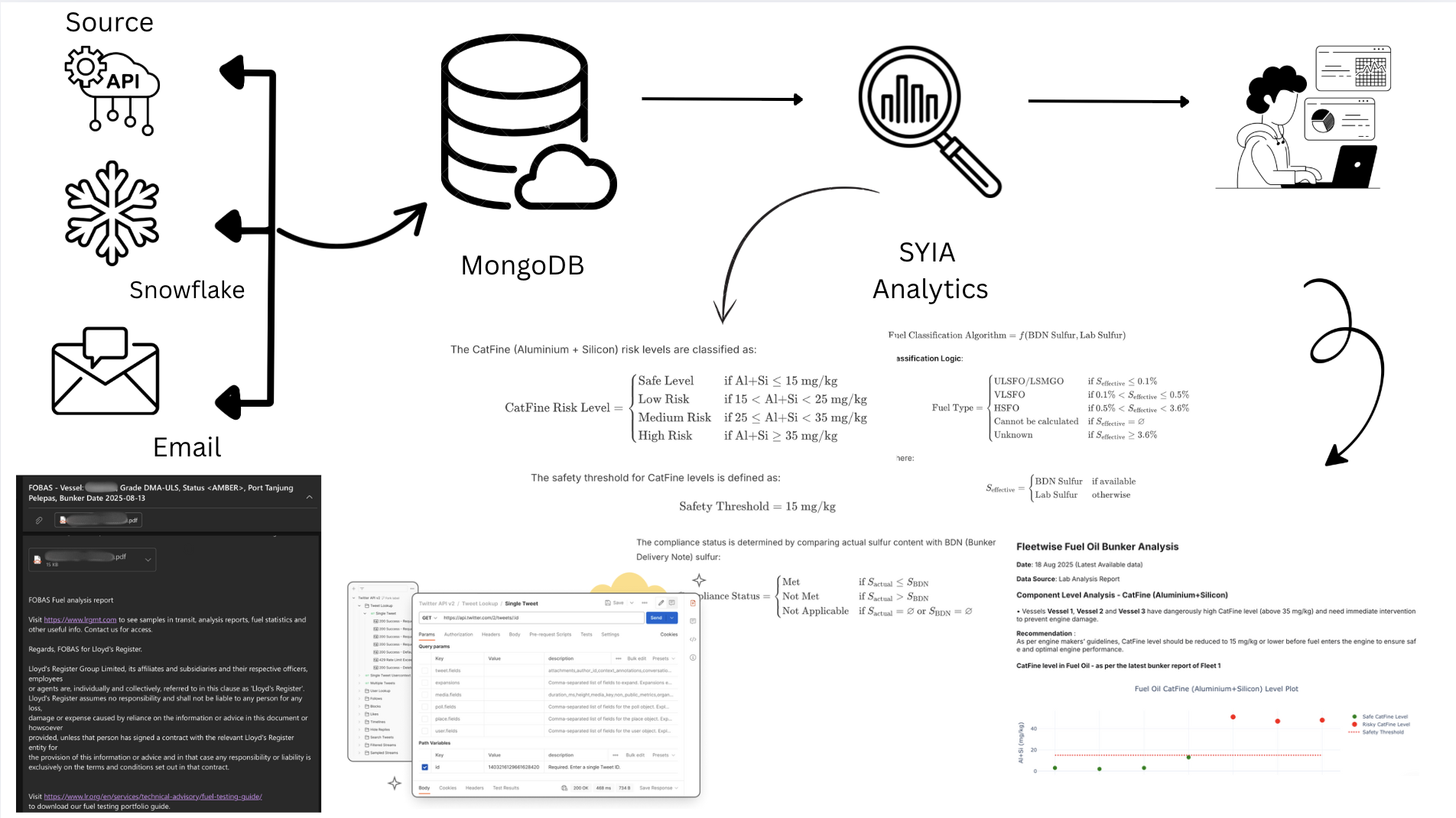
System Architecture & Data Flow
Laboratory Integration Network
Our module integrates with six leading marine fuel testing laboratories through different data channels:| Laboratory | Integration Method | Data Format | Processing Type |
|---|---|---|---|
| Viswa Labs | API Integration | JSON | Real-time API calls |
| Tribocare | API Integration | JSON | Real-time API calls |
| FOBAS | API Integration | JSON | Real-time API calls |
| VPS Marine | Snowflake Database | Structured Data | Database queries |
| Bureau Veritas (BV) | Email Attachments | XML + Report | XML file extraction |
| Maritec | Email Attachments | XML + Report | XML file extraction |
Process Workflow: Step-by-Step Implementation
Phase 1: Data Acquisition & Integration
Objective: Establish comprehensive fuel oil data collection from multiple laboratory sources using different integration methodsStep 1: API-Based Data Collection
The Challenge: Traditional batch processing approaches failed to handle the dynamic nature of laboratory data updates, leading to data inconsistencies and processing gaps. Our Revolutionary Solution: We engineered an intelligent cyclic data synchronization system that maintains perfect data integrity across all API-based laboratories. Key Innovation: This cyclic approach ensures zero data loss while optimizing API calls and maintaining real-time synchronization across all laboratory sources.Step 2: Snowflake Database Integration
Implementation: VPS Marine Data Extraction Snowflake Integration Features:- Direct Database Connection: Secure connection to VPS Snowflake instance
- Scheduled Queries: Automated data retrieval at regular intervals
- Data Warehouse Access: Access to historical and real-time VPS fuel analysis data
- Query Optimization: Efficient data extraction with minimal resource usage
Step 3: Email-Based Data Processing with XML Extraction
Implementation: BV and Maritec Laboratory Data Email Processing Workflow:- Email Monitoring: Continuous monitoring of designated email accounts
- Attachment Identification: Automatic detection of emails with attachments
- Dual File Processing:
- XML File: Contains structured data for extraction
- Report File: Actual laboratory report for reference
- XML Data Extraction: Automated parsing of XML files to extract fuel analysis data
- Data Validation: Verification of extracted data against laboratory standards
Phase 2: Data Processing & Standardization
Objective: Process and standardize data from multiple sources into unified formatStep 4: Multi-Source Data Processing
⚡ API Data Processing
JSON parsing for real-time API data with advanced features:
- ✓ Dynamic Page Detection: Automatically reads total page count from API responses (Tribocare)
- ✓ Comprehensive Iteration: Systematically processes every page without data loss
- ✓ Memory-Efficient Accumulation: Optimally manages large datasets during collection
- ✓ Intelligent Job Discovery: Automatically identifies all relevant job IDs within specified date ranges (FOBAS)
- ✓ Automatic Token Refresh: Seamlessly handles token expiration with zero data loss
- ✓ Retry Logic: Implements exponential backoff for maximum reliability
- ✓ Parallel Processing: Optimizes throughput while respecting API rate limits
❄️ Snowflake Connector
Direct database connectivity for VPS data with enterprise-grade features:
- ✓ High-Performance Queries: Optimized SQL execution
- ✓ Secure Connections: Enterprise-level security protocols
- ✓ Automated Scheduling: Time-based data extraction
- ✓ Data Warehouse Integration: Seamless historical data access
📧 Email Parser
IMAP/POP3 protocols for email attachment processing:
- ✓ Real-time Monitoring: Continuous email surveillance
- ✓ Smart Filtering: Intelligent attachment detection
- ✓ Multi-account Support: Simultaneous email monitoring
- ✓ Secure Processing: Encrypted email handling
📄 XML Parser
Advanced XML processing for BV and Maritec data:
- ✓ Schema Validation: XML structure verification
- ✓ Data Extraction: Intelligent content parsing
- ✓ Error Handling: Robust exception management
- ✓ Format Standardization: Unified data output
Step 5: Data Validation & Quality Assurance
Validation Framework:- Schema Validation: Ensuring data conforms to expected structure
- Data Type Verification: Confirming correct data types for all fields
- Range Checking: Validating fuel parameters are within acceptable ranges
- Duplicate Detection: Identifying and handling duplicate test results
- Missing Data Handling: Managing incomplete or missing data points
Step 6: Data Transformation & Standardization
Transformation Process:- Unit Standardization: Converting all measurements to standard units
- Field Mapping: Mapping laboratory-specific fields to unified schema
- Data Enrichment: Adding metadata and processing timestamps
Phase 3: Database Storage & Management
Objective: Efficiently store processed data in MongoDB with proper indexing and organizationStep 7: MongoDB Storage Architecture
Storage Features:- Indexing Strategy: Optimized indexes for fast query performance
- Data Partitioning: Efficient data organization by vessel and date
- Backup & Recovery: Automated backup and disaster recovery procedures
Step 8: Data Repository Management
Repository Features:- Version Control: Tracking data changes and updates
- Audit Trail: Complete logging of all data processing activities
- Data Lineage: Tracing data from source to final storage
Phase 4: Advanced Analytics & Risk Assessment
Objective: Implement sophisticated fuel analysis algorithms for risk assessment and compliance monitoringStep 9: CatFine (Aluminium + Silicon) Risk Categorization System
Implementation Strategy: Our advanced CatFine analysis system extracts concentration data from the latest bunkering operations and applies multi-tier risk assessment protocols. Primary Safety Threshold: A critical threshold of 15 mg/kg is implemented as the primary safety benchmark: Enhanced Multi-Tier Risk Classification: Our system implements three sophisticated risk bands for comprehensive vessel safety management: Risk Level Descriptions:- Safe Level (≤ 15 mg/kg): Vessel operates within optimal safety parameters
- Moderately Elevated (15-25 mg/kg): Minimal risk profile with recommended monitoring protocols
- Elevated Risk (25-35 mg/kg): Requires close monitoring and enhanced fuel treatment procedures
- Dangerously High (> 35 mg/kg): Critical status requiring immediate intervention and emergency protocols
Step 10: Sulfur Compliance Verification System
Compliance Algorithm: Our intelligent compliance system performs real-time comparison between laboratory-tested sulfur values and Bunker Delivery Note (BDN) specifications for each vessel in the fleet. Fleet-Level Compliance Assessment: The system generates comprehensive fleet-wide compliance reports:- Individual Vessel Analysis: Detailed compliance status for each vessel
- Non-Compliant Vessel Identification: Automatic flagging and listing of vessels exceeding BDN limits
- Fleet Compliance Summary: Overall fleet status with full compliance verification
Step 11: Advanced Visualization & Interactive Analytics
Dual-Plot Visualization System: Our module generates two sophisticated interactive plots using Plotly for comprehensive fuel analysis visualization: CatFine Risk Visualization: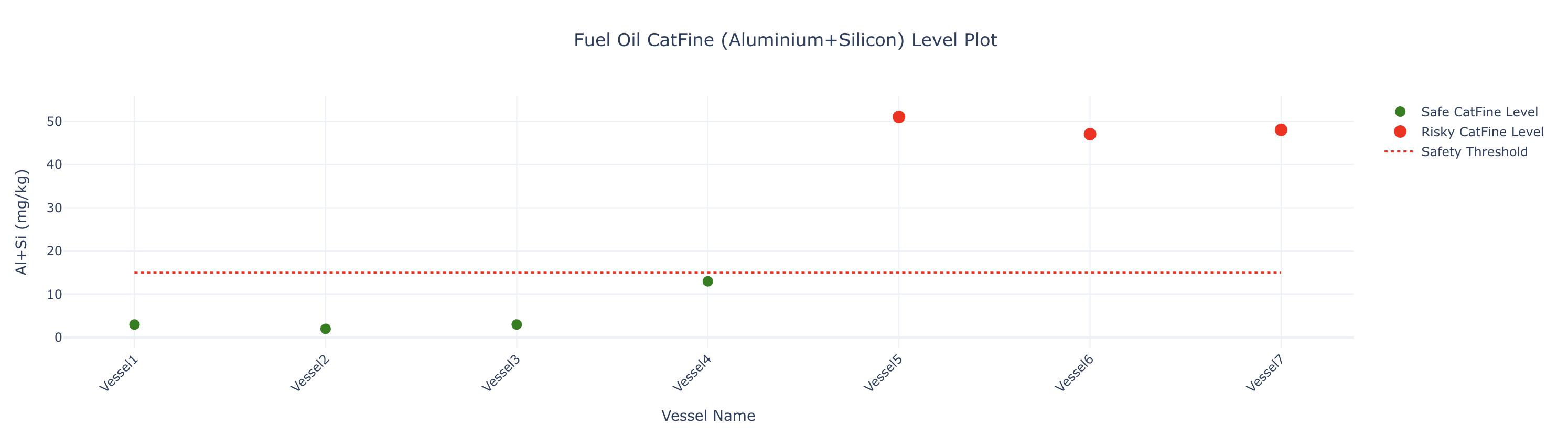
CatFine Level in Fuel Oil - as per the Latest Bunker Report of Fleet 1
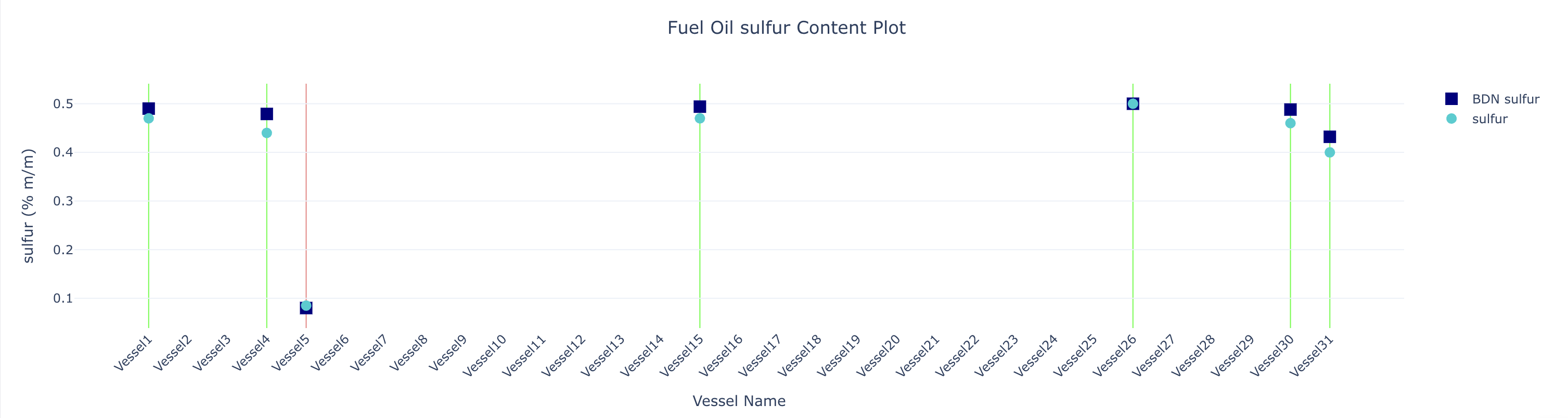
Sulfur Content in Fuel Oil - as per the Latest Bunker Report of Fleet 1
- Interactive Interface: Real-time data exploration with zoom and filter capabilities
- Multi-Parameter Display: Simultaneous visualization of BDN and tested values
- Compliance Indicators: Visual compliance status with color-coded vertical lines
- Threshold Markers: Clear safety threshold indicators for immediate risk assessment